




作者:李昕
人工智能在近几年强势兴起,Nvida股票市值在过去10年从90亿美金直接飙升至1.12万亿美金。爬虫、视频识别、换脸、聊天机器人等等开始迅速影响我们的生活。大家都在讨论什么职业会被AI最先取代,到底Terminator会在哪一年统治世界。
但同时AI肯定不是万能,AI有各种不尽人意的地方。本文希望能从个人角度从底层算法谈谈AI的缺点。并从这些缺点出发,看看未来AI的发展方向,以及我们团队的最新研究成果。
一、AI的起源
AI的起源有各种版本,个人认为发源于古典数学理论的朴素贝叶斯分类器(Naive Bayes Classifier 或 NBC)。其有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。下面的公式也成为AI的源头公式:

但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。从其源头的不完美性,也带来目前AI的一些主要困境。
二、深度学习
深度学习是AI的一个重要分支,无论是Alpha Go还是Chat GPT,其底层算法都是深度学习。深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。
从一个输入中产生一个输出所涉及的计算可以通过一个流向图(flow graph)来表示:流向图是一种能够表示计算的图,在这种图中每一个节点表示一个基本的计算以及一个计算的值,计算的结果被应用到这个节点的子节点的值。考虑这样一个计算集合,它可以被允许在每一个节点和可能的图结构中,并定义了一个函数族。输入节点没有父节点,输出节点没有子节点。这种流向图的一个特别属性是深度(depth):从一个输入到一个输出的最长路径的长度。 下图展示了一个典型的深度学习处理过程。
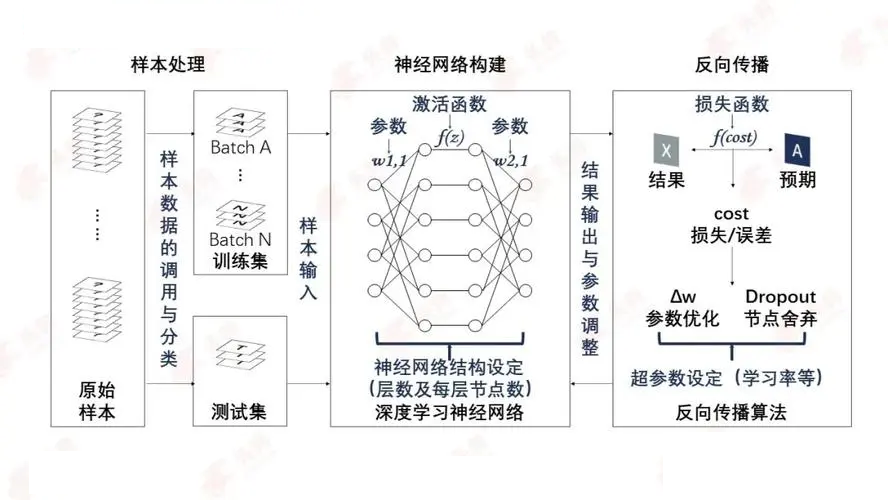
其核心计算过程如下所示:

三、AI的缺陷
理解了AI的起源与基本概念,再来看目前AI的困局:
首先,深度学习模拟了人脑二叉树的决策过程,无论对图像、声音、触觉、嗅觉等进行海量数据处理,但其处理过程并非是化学过程,而是大规模集成电路的物理过程,其处理效率肯定远低于人脑。
其次,经过过去几千年的发展,我们的已经产生了一个有框架和发展规律的社会科学模式。例如:当我们进行玛雅人考古时发现,过去几千年玛雅人诞生了辉煌的石器文明,他们可以把金子加工到纸的20分之一厚,用1700度高温(十九世纪才诞生了可以保持此温度的熔炉)加工铂金,但他们居然没发明轮子。我们只是站在上帝视角去看玛雅人,但我们的工业体系也有许许多多类似的困局,目前AI的发展基本都局限于拟人化,例如视频识别张三、李四;无人驾驶来代替司机。目前AI并不能帮我们发现轮子。
再次、人类经过数十万年的进化与发展,我们消退了很多能力,例如:感知地震。但我们对一些事物敏锐观察感知能力,也不是AI在短短几十年就能弥补上的。例如L5级的无人驾驶,目前来看真正实现的时间尺度还要数十年这个尺度。
最后,现在的AI对数据标注、训练的严重依赖,也使得其发展大大受限。在AI早期一直有个名词“自学习”,号称数据量越大模型精度将越高。实际AI发展过程中噪声对AI的影响非常之大,如果数据量增大,噪声也会影响模型精度。AI还远做不到自我标注、自我学习的能力。
四、AI的未来
谈到了缺陷也谈谈我们对AI未来的应对与展望:
首先,一定不能唯AI论,在很多时候AI算法并不能替代传统基于时序的小波变换、卡尔曼滤波、最小二乘等算法。这些基于频谱、时序的算法在数据预处理方面有着非常重要的能力。例如:梅尔变换是所有音频处理的必要前置手段,近些年EMD算法在音频的傅里叶转换中也开始崭露头角。在变频电机、负载分析中,小波变换一直有着重要的地位。目前许多案例都证明,用经典算法对数据降噪、滤波后,AI模型的精度会得到大幅上升。
其次、目前AI的确不具备跳出标注框架来发明新的方法,但通过数值模拟,噪声引入等方法,可以更多的扩展思路。我们团队一直致力于将AI引入PID控制过程,为每一台变频电机打造个性化的控制方法,保证在个性化场景中,电机具备节能、调速功能,即保证了其节能性、也保证了更少维护量。
再次、对于AI进行多元复杂数据处理,尤其是多传感器融合性差的问题。我们更多引入经典数据处理与AI算法结合的模式,例如ABCD四个输入源,先用经典算法、机器学习等进行数据预处理,之后引入深度学习进行二次处理,最后在利用DTF、高通滤波等进行终处理。有效提高AI能力。
最后、目前的AI无法进行自学习,但是可以自标注。利用在过程中出现的结果,将正确结果结算、滤波处理后整理成标签数据,再将其与之前的原始数据混合,进行新模型的生成。通过对新模型与老模型的精度比较,实现将精度更高的模型留存目的。
| 1.作者简介 李昕,男,汉族,1978年生,中国矿业大学(北京)计算机应用技术博士,榆林学院客座教授,2002年-2004年留学日本,曾先后就职于日本住友集团、中国网通集团、澳大利亚电信公司等世界500强企业,现任北京龙田华远科技有限公司董事长。 李昕教授拥有20年以上丰富的产品研发、市场营销、项目管理经验,曾领导并成功完成了APCN2中日海底光缆扩容项目、2008北京奥运会高清电视转播项目、华为全球MPL S网络建设工程等大型跨国项目。 2018年李昕教授带领团队参与科技部“国家十三五科技重大攻关项目——千万吨级特厚煤层智能化综放开采关键技术及示范(2018YFC0604500)”并成功交付首套基于国产惯导的采煤机定位系统。 2022年获评中国岩石力学与工程学会煤矿智能开采与岩层控制分会第七届理事会常务理事。 2.作者成果 2017年、2020年、2021年分别获得煤炭工业协会科技进步三等奖1项、二等奖2项 累计发表核心论文5篇,获得发明专利2项,实用新型专利7项,煤炭工业协会科技进步奖3项,授权软著74项 |
北京龙田华远科技有限公司
煤矿智能化领导者关注我们

